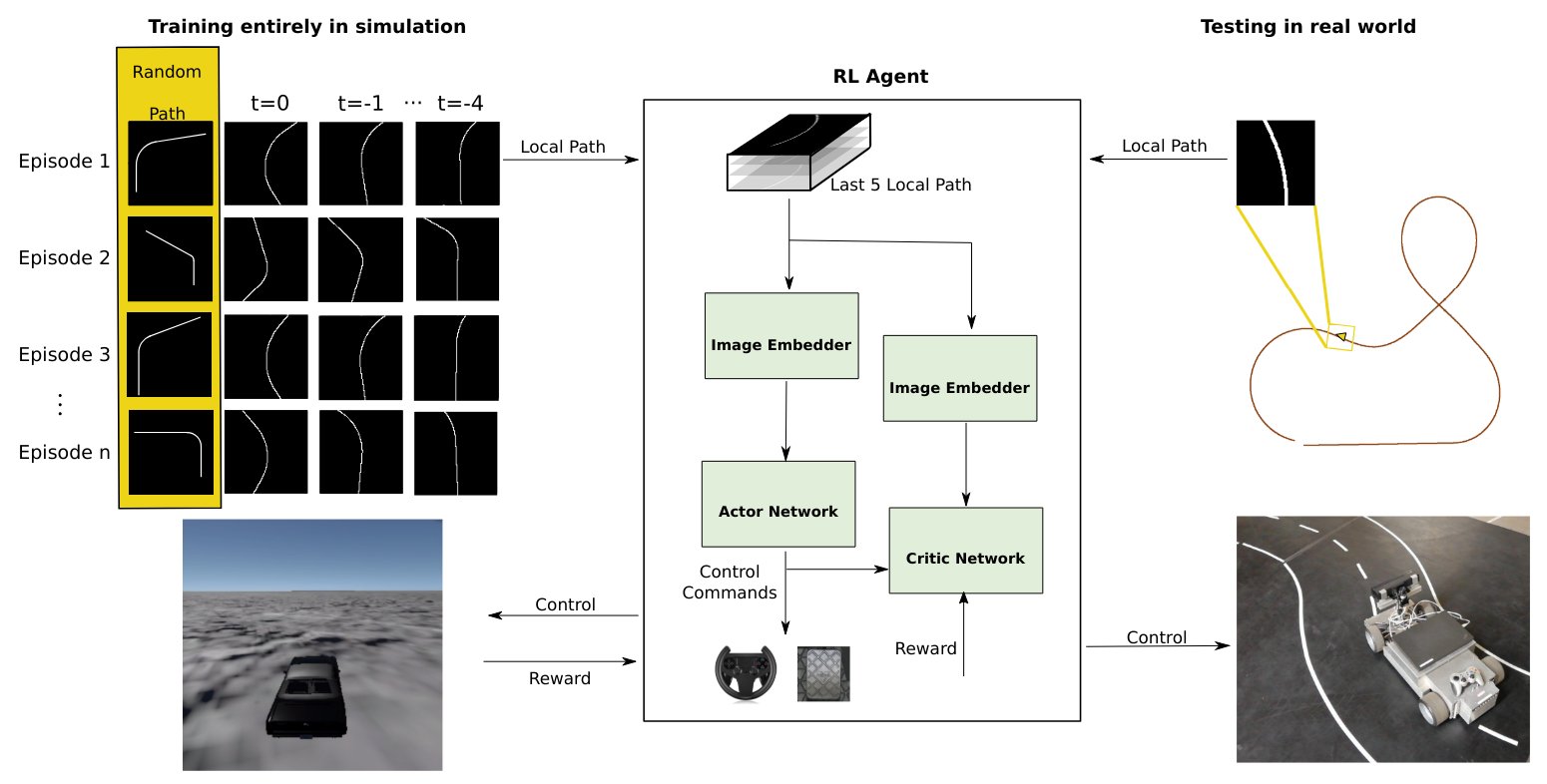
publications
2025
- NeurIPS
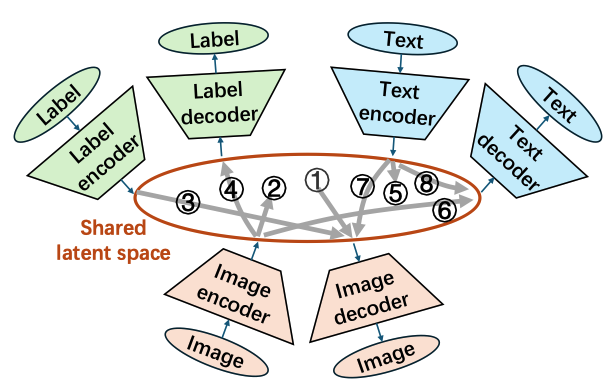 Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification2025
Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification2025 - WACV
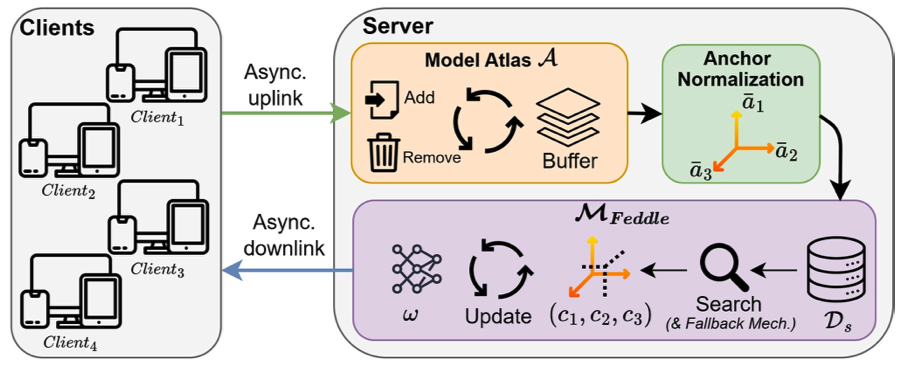 Guided Model Merging for Hybrid Data Learning: Leveraging Centralized Data to Refine Decentralized Models2025
Guided Model Merging for Hybrid Data Learning: Leveraging Centralized Data to Refine Decentralized Models2025 - ICLR
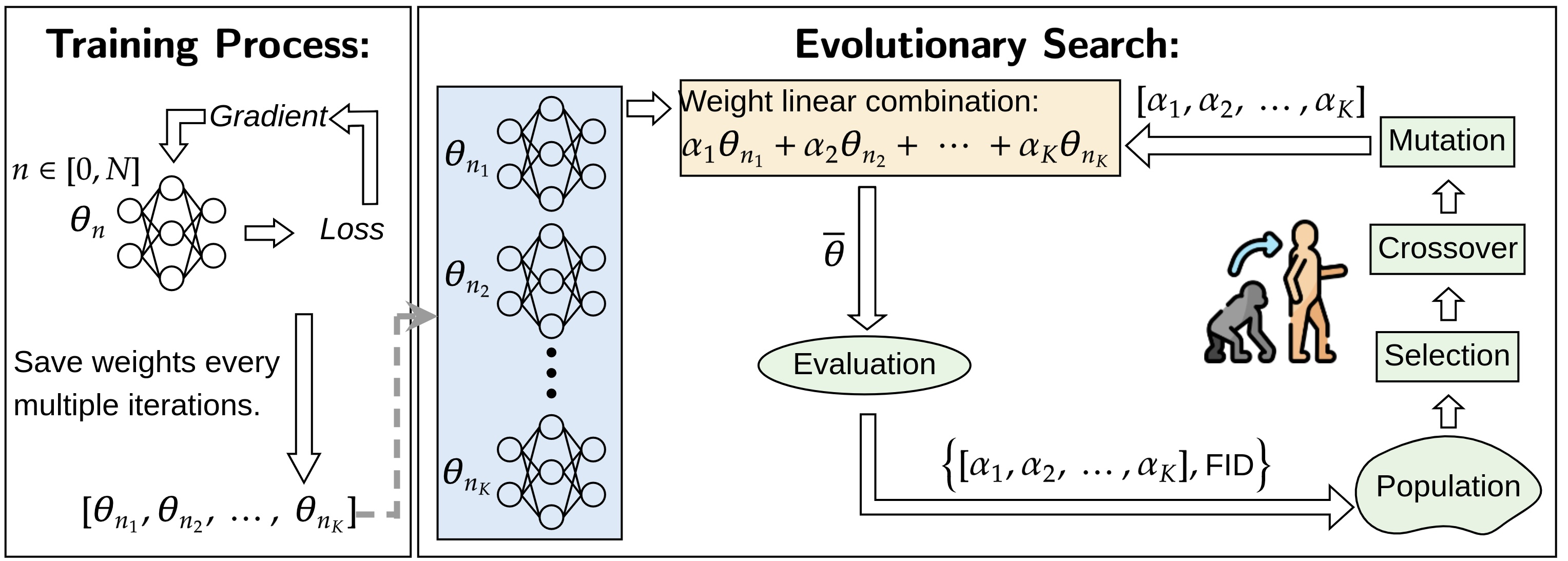 Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better2025* = Co-first authors
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better2025* = Co-first authors



2024
- arXiv
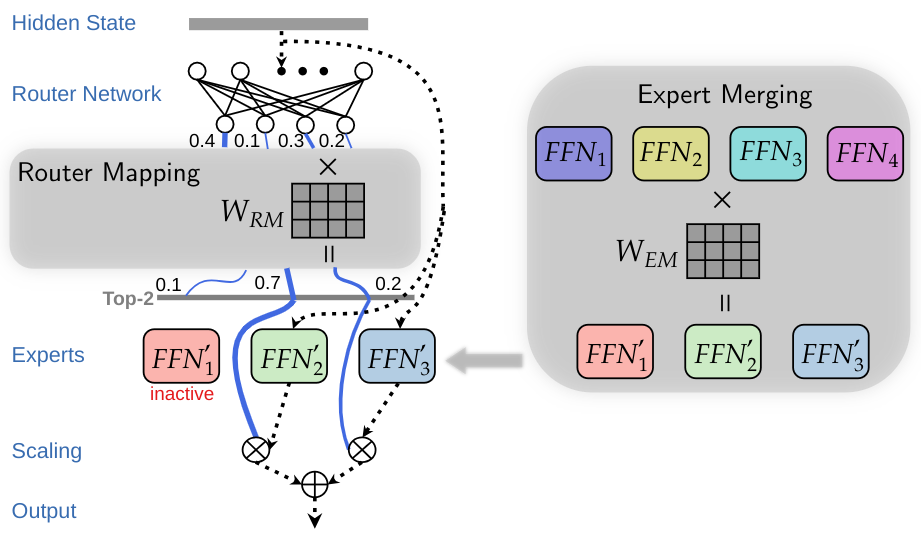 Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs2024* = Co-first authors
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs2024* = Co-first authors - EMNLP Findings
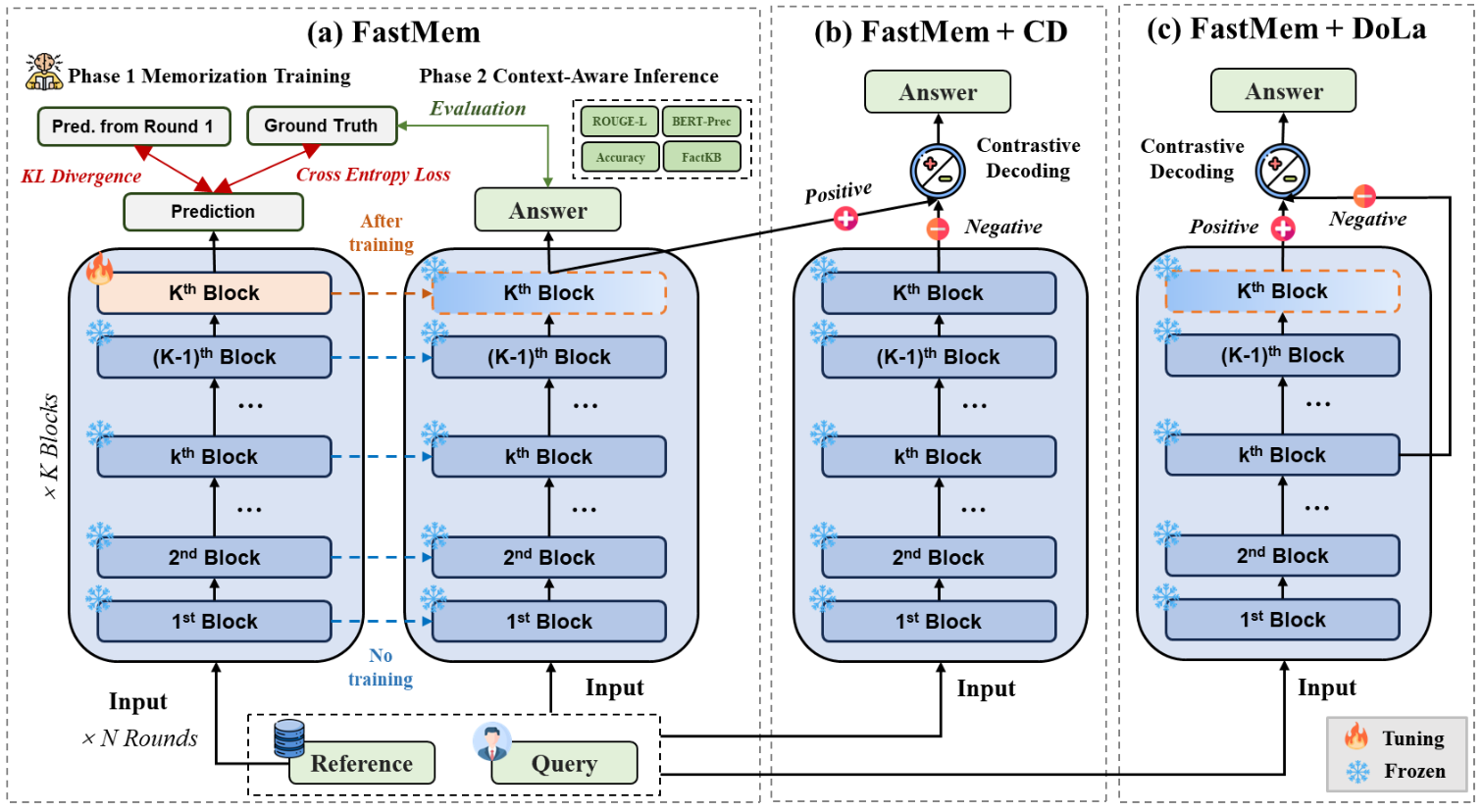 FastMem: Fast Memorization of Prompt Improves Context Awareness of Large Language Models2024* = Co-first authors
FastMem: Fast Memorization of Prompt Improves Context Awareness of Large Language Models2024* = Co-first authors - Tiny Paper@ICLR
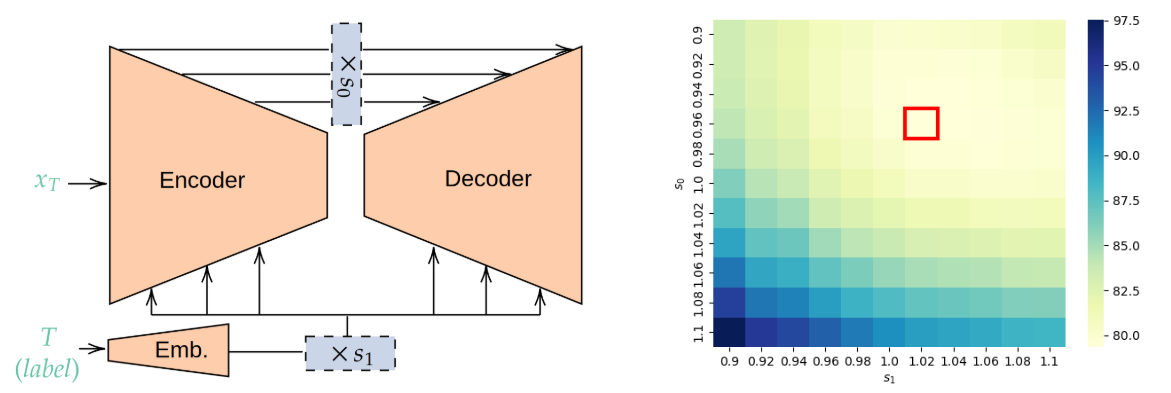
- TMLR
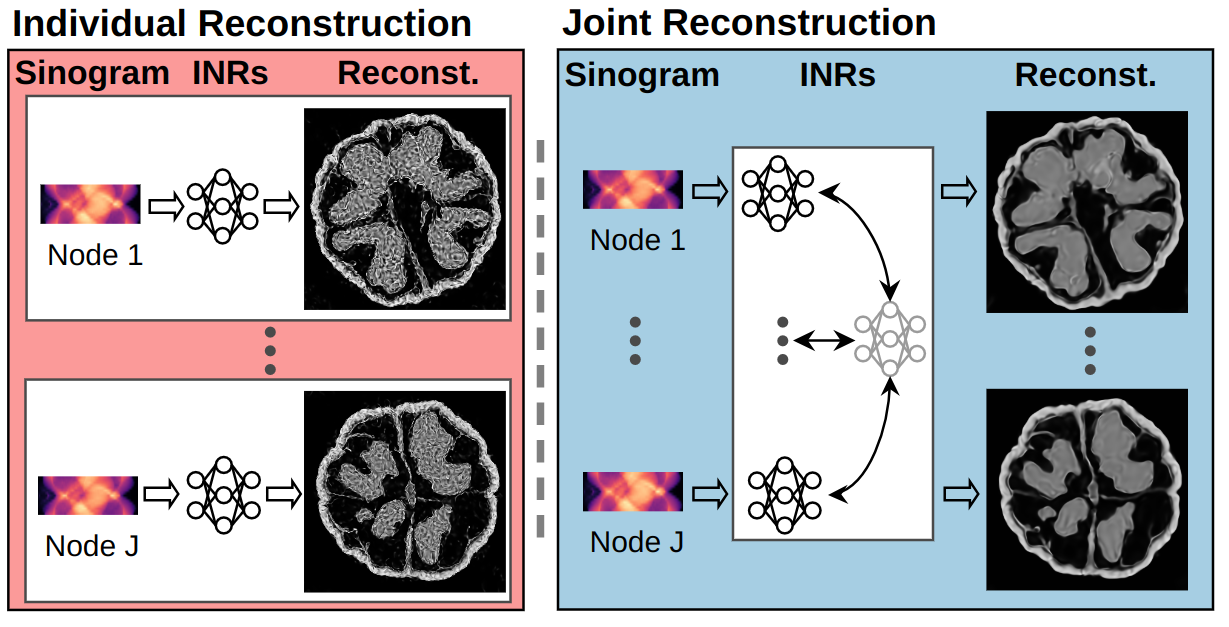 Implicit Neural Representations for Robust Joint Sparse-View CT Reconstruction2024* = Co-first authors
Implicit Neural Representations for Robust Joint Sparse-View CT Reconstruction2024* = Co-first authors




2023
- CVPR
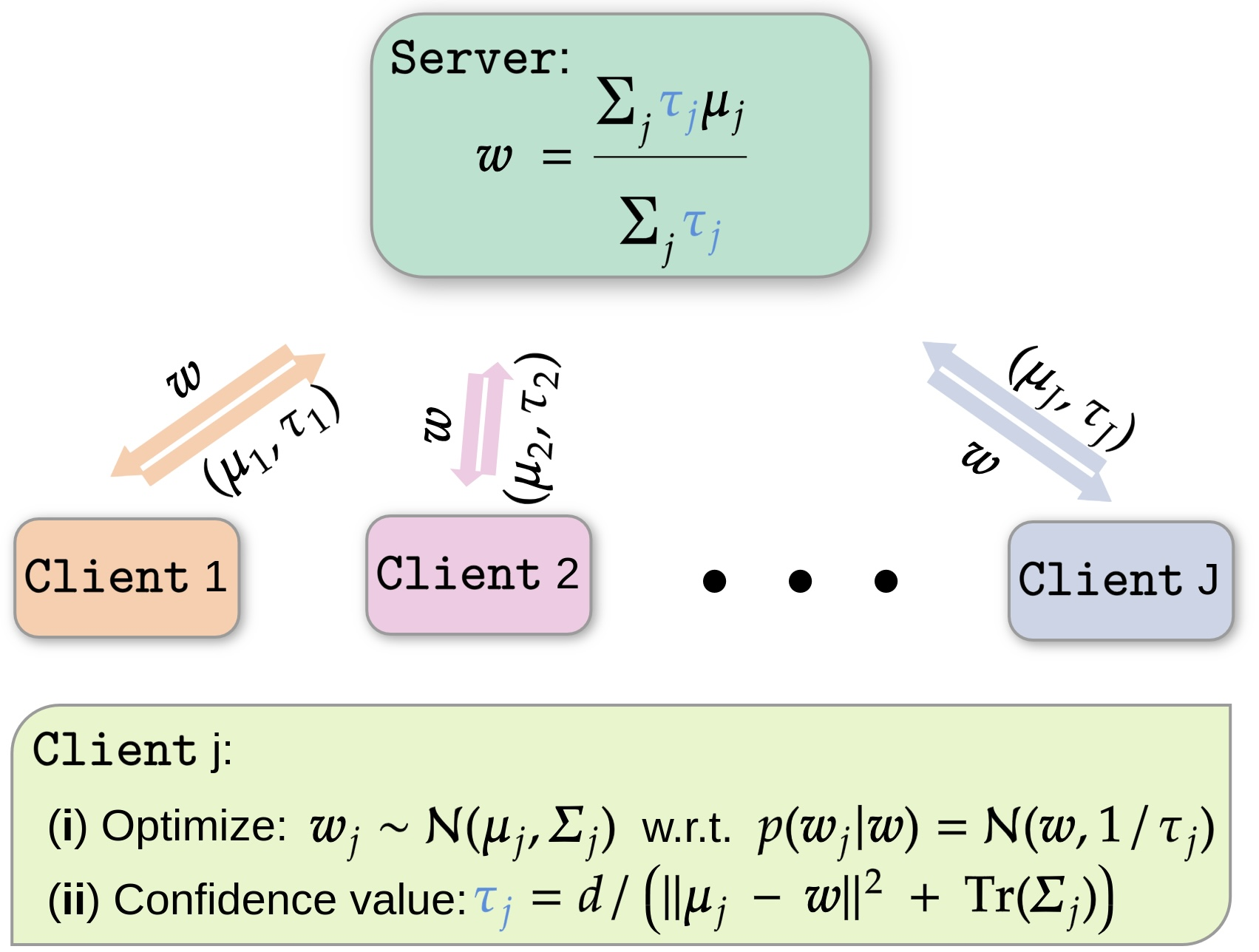 Confidence-aware Personalized Federated Learning via Variational Expectation Maximization2023* = Co-first authors
Confidence-aware Personalized Federated Learning via Variational Expectation Maximization2023* = Co-first authors - ICML
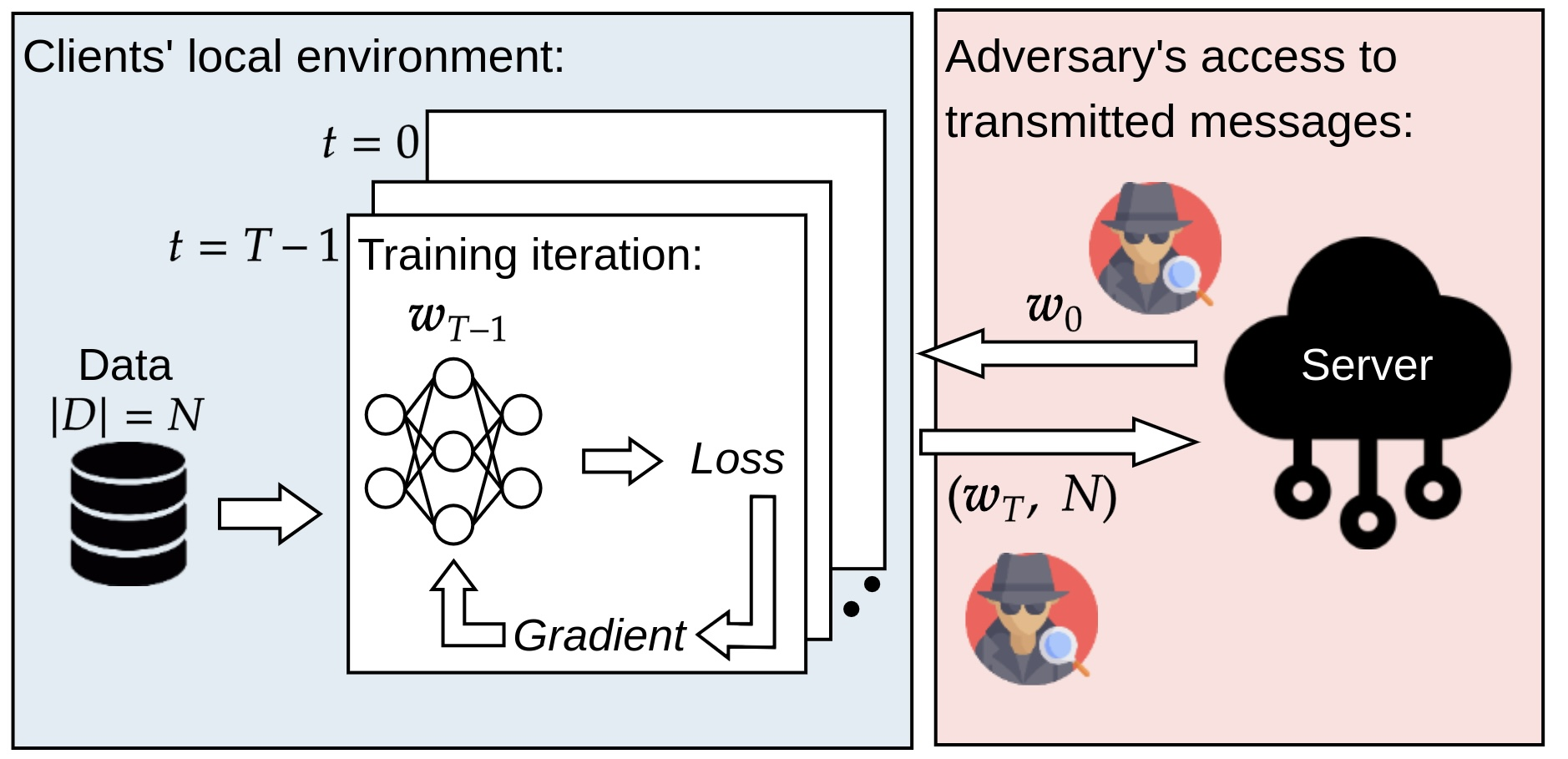 Surrogate Model Extension (SME): A Fast and Accurate Weight Update Attack on Federated Learning2023
Surrogate Model Extension (SME): A Fast and Accurate Weight Update Attack on Federated Learning2023 - TMLR



2021
- ICLR


2019
- ITSC
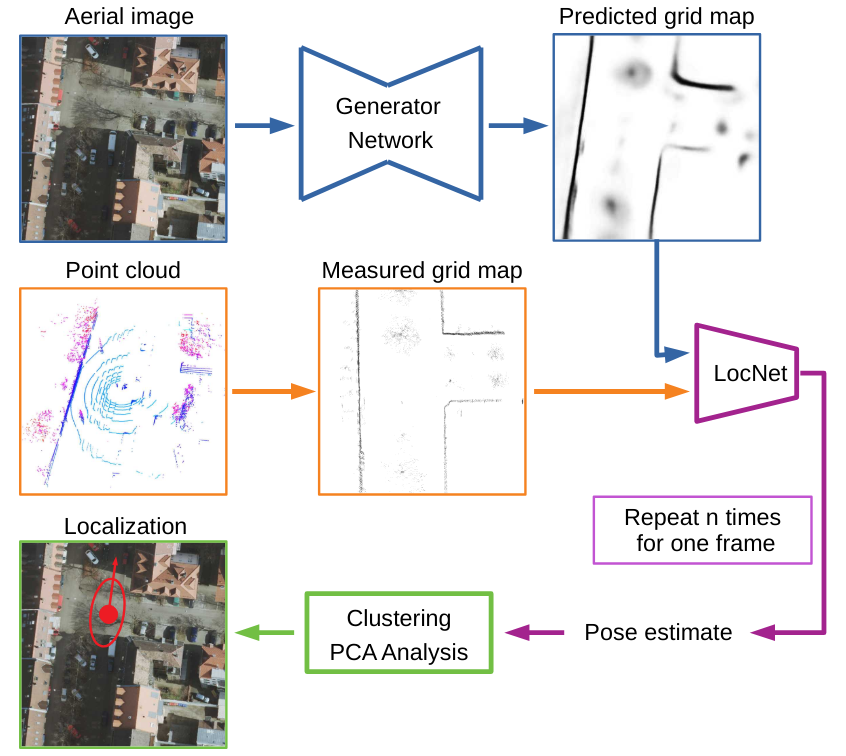
- ECMR